
Hoe bereid je je voor op een deelname aan een quiz? Je kunt je breed oriënteren, het nieuws een beetje bijhouden, wat apps spelen, en af en toe een boek openslaan. Toen ik deelnam aan een quiz, pakte ik het nog wat anders aan. Na een eerder artikel met wat algemene overwegingen rondom het voorbereiden van mijn quizdeelname treed ik nu wat meer in detail over hoe ik mezelf heb getraind, welke inzichten rondom mijn kennisniveau ik gaandeweg op deed, en welke manier van uitvragen mogelijk beter of slechter werkt.
Vragen vragen
(Ik begin redelijk in medias res en ik heb geen zin om elke term opnieuw uit te leggen, dus ik raad je aan om eerst het eerdere stuk te lezen voordat je verder gaat.)
Om mezelf te toetsen formuleerde ik in totaal formuleerde ik 4.449 vragen, verdeeld over tien categorieën (zie onderstaande tabel).1 Ik ontwierp – uiteraard – een Excel waarin elke quizvraag aan mij werd getoond in de vorm van een gap task. Nadat ik het ontbrekende woord had ingevuld, werd het juiste antwoord zichtbaar, werd dit antwoord vergeleken met mijn invoer, en bij een gelijkenis werd een antwoord goed (1) of fout (0) gerekend.
| Categorie | N |
| Humanities & Social Sciences | 645 |
| Literature | 634 |
| Media & Entertainment | 537 |
| Geography | 520 |
| Life & Medical Sciences | 461 |
| Arts & Design | 419 |
| Contemporary | 418 |
| STEM & Physical Sciences | 353 |
| Culture | 315 |
| Sports | 147 |
| Totaal | 4.449 |
Deze vragen heb ik in totaal 20.180 aan mezelf uitgevraagd, over een periode van ongeveer zes maanden. Ik was tevreden met mijn score per quizvraag als ik de vraag tenminste 66% van de keren goed heb beantwoord na 3 keer vragen. Bij een score hoger dan 66% werd de vraag niet meer getoond in het Excelbestand. Maar als de score lager was, dan bleef de vraag net zo lang terugkomen tot het aandeel van 66% goed beantwoord bereikt was.2
Aan het einde van de rit beantwoordde ik 57% van mijn quizvragen goed. Dat ging niet in elke categorie even lekker. Hieronder zie je het aandeel goed beantwoorde vragen per categorie. Hieruit blijkt dat ik redelijk goed zat op het gebied van culturele begrippen, mediagerelateerde vragen en sport. Aan de onderkant blijkt dat ik minder goed was in het paraat hebben van begrippen uit de medische wetenschap, geografie, de geesteswetenschappen en de sociale wetenschappen.3

Onderstaande figuur toont het aandeel goed beantwoorde vragen, uitgesplitst voor hoe vaak de vraag is gesteld. Hieruit blijkt dat ik een vraag, bij eerste blootstelling, zo’n 40% van de keren goed kon beantwoorden, en dat dit oploopt tot 67% bij de derde keer stellen.
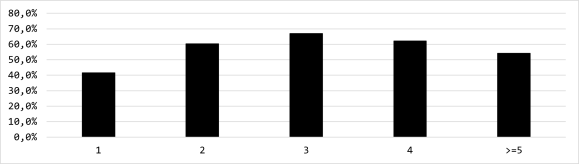
Hierboven zie je ook dat na de derde keer het aandeel ‘goed beantwoord’ juist weer afneemt. Er waren genoeg ‘hardnekkige vragen’: vragen die 5 keer of meer gesteld zijn. Sommige vragen heb ik meer dan twintig keer gezien (het onderscheid tussen duindoorn en sleedoorn kan ik nog steeds niet onder woorden brengen). Hieronder zie je het aandeel ‘hardnekkige’ vragen per categorie, die redelijk gelijk loopt met de bovenstaande figuur met het aandeel goede antwoorden per categorie.

Patronen, of: het gebrek daaraan
Ik houd niet alleen van Excel (zie bijvoorbeeld 1, 2, 3, 4, 5), ik ben ook niet vies van een beetje patroonherkenning in data. Daarom vond ik het leuk om aanvullend te kijken naar patronen in de mate waarin ik vragen goed wist te beantwoorden.
Omdat ik steeds naar het aandeel vragen dat ik goed had beantwoord kon kijken, kon ik ook zien in hoeverre mijn prestaties in de loop der tijd verbeterden. Lekker motiverend, dacht ik.
Mooi niet. Hieronder zie je het aandeel vragen dat ik goed had per deciel van de totale dataset (dus van vraag 1 tot vraag 20.180). Ik had graag een rechte lijn omhoog gezien, maar dat was heel lang niet het geval.4,5
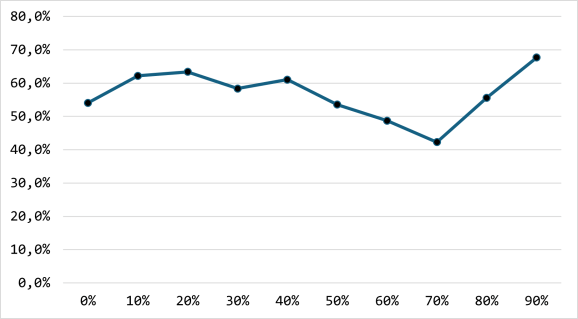
Wat maakte dat ik vaker goed ging antwoorden? Ik had wat vage indicaties, maar ik wilde kijken of ik misschien ook aanpassingen kon doen in de vraagvolgorde, om tot betere resultaten te komen. Daarom keek ik eerst of het uitmaakte of ik een vraag vaker goed had als ik die vraag recenter had gezien. Dat was niet zo. Ook bleef het aandeel goede antwoorden gelijk als ik meer vragen uit één categorie achter elkaar kreeg te zien.6
Wel lijk ik relatief beter te antwoorden als ik de 25 voorgaande vraagstellingen rond dezelfde tijd heb ingevoerd als de gestelde vraag (zie onderstaande figuur).

Mogelijk komt dit door het zogeheten encoding specificity-principe.7 Denk maar eens aan hoe je ooit een Frans rijtje probeerde te stampen. Weet je nog hoe het supergoed werkte als je alle woordjes op steeds dezelfde volgorde opdreunde, maar het ineens veel moeilijker werd als je het rijtje willekeurig ging toetsen? Nou, dan weet je ’t wel.
Dus of ik deze methode zou aanbevelen voor een duurzaam leereffect: mwa. Want quizvragen in het wild worden ook niet op een vaste volgorde gesteld.
Slot
In dit artikel schetste ik wat meer in detail hoe mijn voorbereiding op een quiz eruit zag, welke inzichten ik tussentijds en achteraf in mijn kennisniveau kon krijgen, en welke patronen ik (niet) zag in wanneer ik vragen vaker goed beantwoordde.
En, heeft al dat trainen mij nu in de praktijk geholpen om beter te quizzen? Nauwelijks. Op het moment supreme kreeg ik 36 vragen, en in mijn herinnering was er precies één vraag die ik herkende uit mijn vragenset. Helaas werd dus bevestigd wat ik al dacht: je gaat niet het antwoord op elke quizvraag paraat hebben, tenzij je er minstens 15 jaar lang 4 uur per dag voor oefent. En dan nog.
Maar het zorgde wel voor een boel voorpret! En een beetje horizonverbreding is natuurlijk altijd mooi meegenomen.
Ik vraag geen geld voor deze blog, maar als je dit leuk of nuttig vond en me financieel wil steunen, dan mag dat natuurlijk! Dat doe je via ↗️️Buy Me A Coffee. Veel dank!
- De categorieën zijn een beetje gaandeweg ontstaan, en verder niet getoetst op validiteit en betrouwbaarheid, maar dat was ook niet de insteek van dit huis-tuin-en-keukenonderzoekje. ↩︎
- Een klein aantal vragen heb ik tijdens het uitvragen uit de roulatie gehaald omdat ik ze bij nader inzien toch te specifiek vond voor een algemene quiz. Zoals de hoofdstad van Samoa. ↩︎
- Niet in elke categorie was het kennisniveau gelijk. Sommige begrippen in de categorie Culture waren enorme gemeenplaatsen, terwijl sommige namen in bijvoorbeeld de geografie wel erg specifiek konden zijn. Zoals alle hoofdsteden ter wereld. Ja, ook die hoofdstad van Samoa. ↩︎
- Dit gebrek aan rechte lijn geldt helaas ook voor elke afzonderlijke vraagcategorie. ↩︎
- Overigens vermoed ik dat het door de organische totstandkoming van de vragenlijst komt. Misschien was de rechte lijn beter zichtbaar geweest als ik een vaste vragenlijst zou aanhouden vanaf het begin, en hier niet meer aan zou zitten. Maar dit is uiteraard niet het geval geweest: elk moment dat ik oefende, bedacht ik wel weer een nieuwe relevante vraag om de set te verrijken. Soms deed ik bovendien ook aanpassingen in de vraagstelling om de vraag iets specifieker te krijgen. In eerste instantie waren sommige vragen bijvoorbeeld van het kaliber “nobelprijswinnaar literatuur 1907”. Dat zijn te weinig clues voor mijn simpele brein. Dan voegde ik er bijvoorbeeld maar een boektitel aan toe. ↩︎
- De resultaten waren zo summier dat ik ze niet in dit artikel laat zien. Maar mocht je interesse hebben, zoek dan vooral contact. ↩︎
- Dit principe had ikzelf niet paraat; hier heeft Chat me op gewezen. ↩︎




